The production line comes to a halt. The shift supervisor calls the maintenance department. The technician asks who last repaired the machine. It turns out that the technician in question left two months ago. The diagnosis starts from scratch, and the line remains idle for another three hours. Meanwhile, at a plant on the other side of town, an identical machine received a service request; three days earlier, the system generated it automatically after the OEE indicator fell below the norm for two consecutive shifts. Production wasn’t halted for even a minute. This is no coincidence. It’s the result of a different maintenance strategy. In this article, you will learn: the differences between reactive, preventive, and predictive maintenance, when each strategy makes sense in a manufacturing plant, why prediction isn’t always the best choice, how a CMMS supports the maintenance department, how to choose a maintenance strategy for different machines and workstations.
What are maintenance strategies?
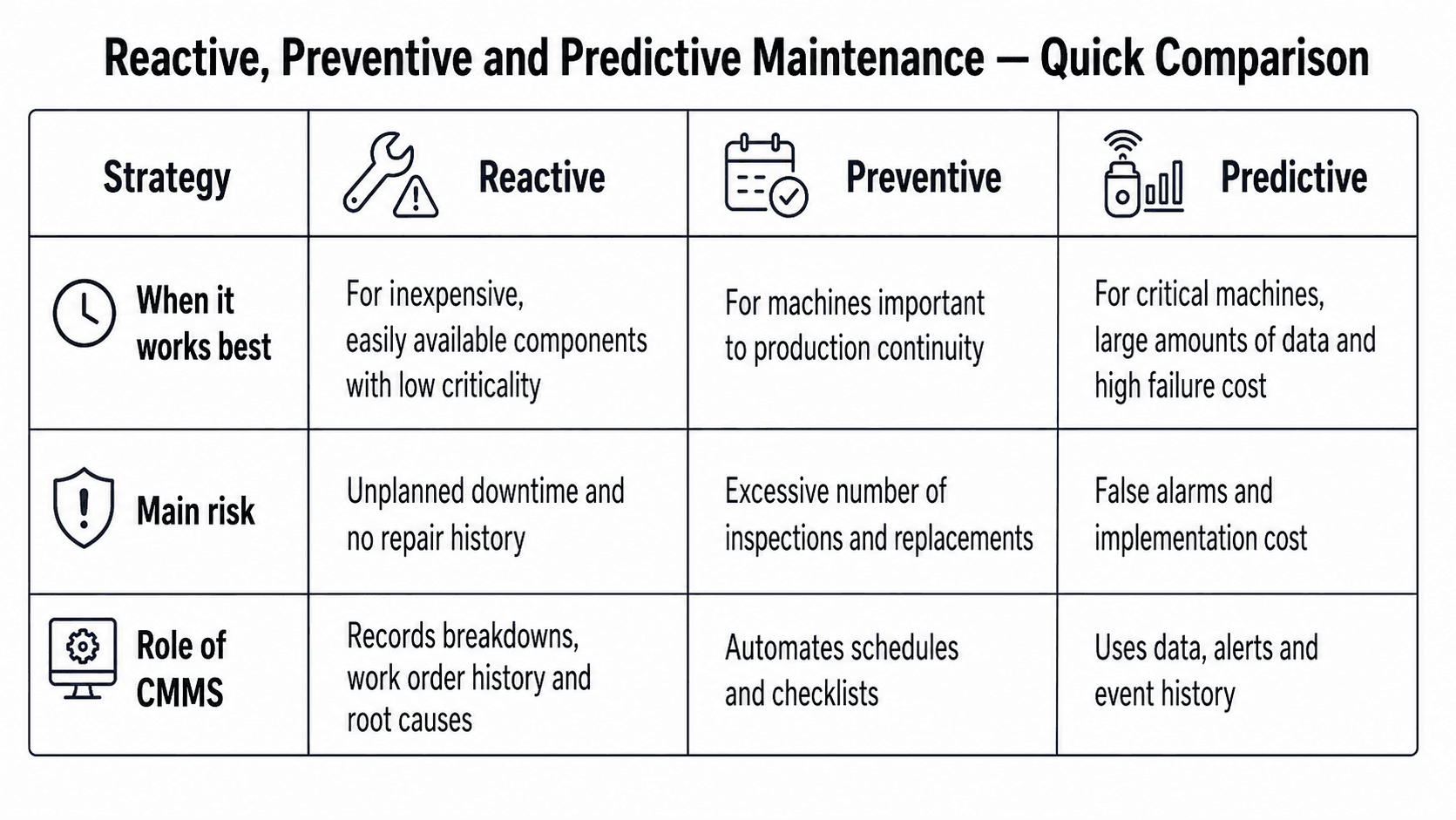
Choosing a maintenance strategy is one of the decisions that directly impacts the reliability of the machinery fleet, the availability of production lines, and the plant’s operating costs. Reactive, preventive, and predictive maintenance are not fads or simple stages of evolution that every company must go through in sequence. They are three distinct approaches with different requirements, implementation costs, and areas of application. The ISO 14224 standard defines maintenance strategies in terms of planning. Reactive maintenance, or corrective maintenance, is performed after a failure is detected. Preventive maintenance is performed at predetermined intervals or based on technical condition criteria [1]. Predictive maintenance is an extension of the preventive approach: an inspection or intervention is planned when data indicates a deteriorating condition of the machine, rather than simply because it is due according to a schedule.
Reactive maintenance. When the low-cost model turns out to be expensive.
Reactive maintenance, also known as run-to-failure, involves taking action only after a failure occurs or a machine’s performance drops below an acceptable level. At first glance, this is a low-cost model. There are no schedules, planned downtime, or preventive costs. The maintenance department responds only when the machine actually stops working. In some cases, this is fully justified, especially for low-criticality equipment that is easy to replace and inexpensive to repair. The problem arises when the reactive model is applied to machines that create production bottlenecks or support critical processes. In such cases, reactivity comes at a high cost hidden in downtime, defects, delays, and lost orders.
A study published in the *International Journal of Prognostics and Health Management* by NIST researchers Thomas and Weiss analyzed maintenance practices in the U.S. manufacturing sector. Facilities in the top half in terms of reactive maintenance use reported 52.7% more unplanned downtime and 78.5% more defects than facilities using a preventive or predictive approach. In the same study, plants with a predominantly reactive model incurred 49.4% to 73% higher sales losses resulting from production process disruptions [2]. Reactive repair is also more expensive logistically. Interventions take place under time pressure, often without available parts, without a complete history of previous orders, and without clear information about what happened to the machine previously. The U.S. Department of Energy notes that planned preventive maintenance is typically significantly cheaper than emergency repairs, mainly due to the lack of time pressure, better availability of resources, and a smaller scope of damage [3].
When does reactive maintenance make sense?
A reactive approach may be the right strategy when a component: is of low criticality to the production process, is inexpensive to replace, is readily available in stock, does not cause a domino effect on other parts of the line, does not significantly affect safety or product quality. In other cases, the reactive model should be approached with caution. Just because a company does not incur preventive maintenance costs does not mean it does not pay for breakdowns. Often, it pays more, just in a less visible way.
Preventive maintenance. Planning instead of chaos.
Preventive maintenance involves performing inspections, checks, and replacements according to a set schedule. Inspections can be scheduled at specific intervals, after a certain number of operating hours, or after a certain number of cycles. This is a model familiar to most maintenance managers: monthly inspections, oil changes every 500 hours, quarterly bearing inspections, periodic lubrication of moving parts, and periodic inspections of systems or components. The greatest advantage of preventive maintenance is predictability. The maintenance department does not operate solely in firefighting mode, but plans work, allocates resources, orders parts, and reduces the risk of unplanned downtime. The U.S. Department of Energy reports 12–18% lower maintenance costs for facilities with preventive maintenance in place compared to a reactive approach [3]. In its Workplace Index 2024 report, based on data from maintenance management platforms, Eptura indicates that reactive service calls take on average twice as long as scheduled preventive inspections. This directly impacts MTTR and the duration of downtime [4].
The Main Pitfall of Preventive Maintenance
Preventive maintenance is not, however, a perfect solution. The biggest pitfall of PM is over-prevention. Parts are sometimes replaced according to a schedule, even though they could operate flawlessly for weeks or months to come. Machines are shut down for inspections whose frequency stems more from habit than from data. Technicians perform tasks that do not always have a real impact on reducing the risk of failure. In its 2021 maintenance strategy analysis, McKinsey points out that preventive maintenance is often applied unnecessarily in a significant percentage of cases. This is one of the main arguments for transitioning from schedules based solely on the calendar to an approach based on the actual condition of the machine [5]. Therefore, well-designed preventive maintenance should be regularly reviewed. Schedules should be based on data: failure history, MTBF, MTTR, machine criticality, and downtime costs.
Predictive maintenance. Data instead of a schedule.
Predictive maintenance is generating a great deal of interest in the industry. And for good reason: when it works, it can significantly reduce the number of breakdowns, defects, and unplanned downtime. In the predictive model, intervention is not based solely on a schedule. The decision to perform an inspection or diagnostic is made based on data: changes in machine operating parameters, anomalies, failure patterns, a drop in OEE, recurring failure statuses, or signals from sensors. A NIST study showed that facilities with a predominantly predictive approach had 18.5% fewer unplanned downtimes and 87.3% fewer defects compared to facilities relying mainly on preventive maintenance [2]. These differences can have a significant annual financial impact for a manufacturing facility. However, prediction is not a strategy for everyone and should not always be the first choice.
McKinsey describes the case of an industrial company that implemented a predictive algorithm generating 10% false alarms. Across its entire machine fleet, this resulted in over 1,000 additional service interventions per year. These interventions negated the savings achieved by reducing actual breakdowns [5]. The conclusion is clear: predictive maintenance makes the most sense where the cost of a failure or the safety risk is very high, or where failure patterns are well-recognized and repeatable. In other cases, condition-based maintenance—that is, monitoring the condition without a full predictive model—may be more cost-effective.
Organizational maturity. Why does the order matter?
One of the most common mistakes in maintenance organizations is attempting to implement predictive maintenance without a sufficient data foundation. A company implements a vibration monitoring system, signs a contract with an IoT solutions provider, or launches an analytical algorithm. After a year, it turns out that the sensor data is inconsistent, the event history is practically nonexistent, and technicians do not trust the alerts because they too often turn out to be false. In its report A Smarter Way to Digitize Maintenance and Reliability, McKinsey notes that mature, full-scale PdM implementations in heavy industry required at least two years of work by specialized teams and the development of hundreds of analytical models. The basic level of PdM, based on simple deviation thresholds and anomaly detection, delivers less than 10% of the benefits of a full, mature implementation [6]. Organizational maturity in maintenance can be described in five levels:
Level 1 | Failures and their causes are documented in the system. An incident history is maintained.
Level 2 | Inspection schedules are defined and consistently followed. The CMMS manages work orders.
Level 3 | Historical data is analyzed. The maintenance department identifies patterns of recurring failures.
Level 4 | Alert rules are developed based on the analysis. The system responds to deviations from the norm.
Level 5 | Machine learning algorithms and predictive models utilize large sets of sensor data.
Most manufacturing plants operate at Levels 1–2. This is the right starting point. From there, you can systematically build higher CMMS maturity, provided that data is collected consistently from day one.
How does CMMS support maintenance strategies?
Regardless of a facility’s level of maturity, one thing is common to every effective maintenance strategy: a system is needed that collects data, manages work orders, and provides a clear overview of the condition of the machinery fleet. Without such a system, every breakdown begins with the question: who last repaired this machine? A CMMS system streamlines the work of the maintenance department. It allows you to log breakdowns, create work orders, assign tasks to technicians, schedule inspections, store intervention history, and analyze metrics such as MTTR, MTBF, or the number of recurring faults. In AndonCloud, the CMMS module integrates directly with the Andon system. A change in workstation status by an operator or exceeding a defined alert threshold can automatically generate a work order in CMMS, without manual intervention.
The Maintenance Department receives a task assigned to a specific person, along with the category, priority, and history of previous incidents at that location. This allows production and maintenance to work with the same data in real time.
CMMS in the reactive model
In the reactive model, CMMS does not prevent breakdowns, but it streamlines the response to them. Each corrective work order is created and documented in the system. The technician can view the history of previous repairs, the causes of breakdowns, the parts used, and the time it took to restore the machine to operation. As a result, the next intervention does not start from scratch. Over time, the facility builds a knowledge base of the most common failures, the most problematic machines, and the actual costs of reactive maintenance.
CMMS in the Preventive Maintenance
Model In the preventive maintenance model, CMMS automates inspection schedules. Recurring work orders are generated according to a set schedule: at specific intervals, after a certain number of operating hours, or upon completion of the previous work order. Procedure templates and checklists ensure that the technician performs the correct steps in the established order. The system sends reminders about deadlines, assigns tasks, and allows you to analyze whether the schedules actually reduce breakdowns.
CMMS in a Predictive Model
In a predictive model, the CMMS serves as the data foundation. Work order history, MTTR times, failure recurrence, root cause categories, machine statuses, and changes in OEE metrics form the basis for building alerts and more advanced predictions. In AndonCloud, alert rules can respond to deviations from the norm: a recurring failure status at the same workstation, a drop in OEE below the threshold over several shifts, or an atypical downtime pattern. The system can then create a diagnostic work order before a complete failure occurs. It is precisely this history that forms the basis for realistic predictions. Not from an algorithm purchased from an external vendor, but from your own knowledge base about your own machine fleet.
How to choose a maintenance strategy in practice?
Choosing a maintenance strategy is not a one-time decision. It should be tailored to the criticality of individual machines, the availability of data, and the organizational maturity of the maintenance department.
1. Start by assessing the criticality of your machines
Not every machine in the plant requires the same strategy. Equipment critical to production continuity should be managed using a preventive or predictive approach. Auxiliary machines, with readily available spare parts and low downtime costs, can operate under a reactive model.
2. Build a history before you start talking about prediction.
Prediction without historical data is an algorithm without context. At least one year of systematic data on failures, repair times, and event patterns is needed for a predictive model to work effectively. The data doesn’t have to come from advanced IoT sensors right away. A starting point could be workstation statuses, order history, OEE, MTTR, MTBF, number of defects, and failure recurrence.
3. Measure before you start changing.
MTTR, MTBF, and OEE should be measured before changing the strategy. Only then, after a few months or a year, can you assess whether the change has actually been effective. Without a baseline, it is difficult to answer basic questions: Do we have fewer failures? Have we reduced repair time? Have we minimized downtime? Have we improved machine availability?
4. Distinguish between MTTR and response time
MTTR measures the time from when a failure occurs until the machine is restored to operation. Response time is the time from when a problem is reported until the appropriate person takes action. It is advisable to measure both metrics separately. An increase in response time often indicates an organizational issue, most commonly delayed communication, a technician’s unavailability, or unclear escalation policies. A high MTTR, on the other hand, may indicate a technical issue, a lack of parts, a lack of procedures, or an insufficient repair history.
5. Review preventive maintenance schedules regularly
PM schedules should not be set in stone. If inspections do not reduce the number of breakdowns, you need to review their scope, frequency, and quality of execution. If parts are being replaced too early, it is worth analyzing the MTBF and extending the intervals. The greatest potential for improvement is often found where inspections are performed “because that’s how it’s always been done,” rather than because the data supports it.
How does AndonCloud help build UR maturity?
AndonCloud integrates the Andon system with a CMMS module, allowing events from the production floor to be automatically converted into work orders for the maintenance department. An operator reports a problem at the workstation. The system records the status, assigns a category, logs the time of the event, and can generate a service order. The technician receives the task with its priority, a history of previous events, and the procedure to follow. As a result, the plant not only responds faster to breakdowns but also consistently builds the data history needed for prevention, analysis of recurring issues, and a gradual transition toward predictive maintenance. Want to find out which machines in your facility should operate under a reactive, preventive, or predictive model? Schedule a meeting and learn how AndonCloud integrates the Andon system with a CMMS module and helps maintenance departments build a history of failures, inspection schedules, and alert rules all within a single system.
FAQ
What is reactive maintenance?
Reactive maintenance is a strategy in which service intervention occurs only after a failure has occurred or the equipment’s performance has deteriorated below the required level. This model makes sense for components that are not critical to the production process, are easy to replace, and are inexpensive to repair. It works well where downtime does not cause a ripple effect on other parts of the line. For machines that create bottlenecks or support continuous processes, the reactive model generates hidden costs from downtime, defects, and lost orders.
What is the difference between preventive maintenance and predictive maintenance?
Preventive maintenance is based on schedules, while predictive maintenance is based on data regarding the actual condition of the machine. In preventive maintenance, inspections and replacements are performed at set intervals or after a specified number of cycles, regardless of the current condition of the equipment. In predictive maintenance, intervention is planned when machine health indicators point to an impending risk of failure. Predictive maintenance can be more effective, but it requires historical data, measurement infrastructure, and sufficient organizational maturity.
Is predictive maintenance always cost-effective?
No, predictive maintenance isn't always cost-effective. It delivers the greatest value in situations where the cost of failure is very high and failure patterns are well-identified and predictable.
Where should we start when shifting our UR strategy from reactive to preventive?
The shift from a reactive to a preventive maintenance strategy should begin with the systematic documentation of breakdowns. Each breakdown should be recorded in the system along with the cause, repair time, resources involved, and machine details. Without an event history, it is impossible to analyze patterns, and without analysis, it is difficult to develop a meaningful preventive maintenance schedule. The next step is to assess the criticality of machines and determine which equipment requires preventive maintenance and which can continue to operate on a reactive basis.
What is MTTR, and how does it differ from response time?MTTR, czyli Mean Time To Repair, to średni czas od wystąpienia awarii do przywrócenia maszyny do pracy.
Response time refers to the time from when a problem is reported until the appropriate person takes action. It is advisable to measure both metrics separately, as they highlight different issues. A long response time often indicates an organizational problem, such as delayed communication or a technician’s unavailability. A high MTTR may indicate a technical issue, a shortage of parts, or a lack of clear repair procedures.
What is MTBF, and how can it be used in preventive planning?
MTBF, or Mean Time Between Failures, is the average operating time of a machine between consecutive failures. An increase in MTBF following the implementation of preventive maintenance schedules is one of the first measurable signs that the strategy is working. MTBF also helps optimize the frequency of inspections. If a machine breaks down on average every 120 hours, an inspection every 100 hours may be justified. An inspection every 50 hours, on the other hand, may indicate excessive preventative maintenance and generate unnecessary costs from planned downtime.
How does a CMMS support a preventive maintenance strategy?
CMMS supports preventive maintenance by automating schedules, recurring orders, checklists, and task assignments. In AndonCloud, recurring orders can be generated automatically according to a defined schedule. Technicians do not need to remember the due date. The system creates a task after the previous order is closed or according to the set schedule. Procedure templates with required checklist steps help ensure inspections are performed consistently, regardless of the technician’s experience.
How does AndonCloud integrate the Andon system with the CMMS module?
AndonCloud integrates the Andon system with the CMMS module so that an event on the production floor can automatically generate a work order for the maintenance department. Such an event could be a change in the workstation’s status by an operator, exceeding a defined alert threshold, or a recurring failure pattern. The technician receives a task with an assigned category, priority, and history of previous events at that workstation. This allows the maintenance and production departments to work with the same data in real time.Czy predykcja wymaga drogich czujników IoT?
Predictive maintenance doesn't always have to start with expensive IoT sensors.
A good starting point is the data already available at the facility: workstation status history, OEE metrics, downtime durations, defect counts, MTTR, MTBF, and the recurrence of service requests. Advanced vibration, temperature, and current sensors expand the possibilities, but predictions based on event patterns from the Andon and CMMS systems can provide valuable insights without the need for additional sensor infrastructure.
Sources
[1] ISO 14224:2016. Petroleum, petrochemical and natural gas industries — Collection and exchange of reliability and maintenance data for equipment. International Organization for Standardization.
[2] Thomas, D. and Weiss, B. (2021). Maintenance Costs and Advanced Maintenance Techniques in Manufacturing Machinery: Survey and Analysis. International Journal of Prognostics and Health Management, 12(1). DOI: 10.36001/ijphm.2021.v12i1.2883. PMC9890517.
[3] U.S. Department of Energy (2010). Operations & Maintenance Best Practices Guide. Release 3.0. Federal Energy Management Program.
[4] Eptura (2024). Workplace Index H1 2024 Report. eptura.com.
[5] McKinsey & Company (2021). Establishing the right analytics-based maintenance strategy. McKinsey Operations Practice, lipiec 2021.
[6] McKinsey & Company (2021). A smarter way to digitize maintenance and reliability. McKinsey Operations Practice, kwiecień 2021.
