Linia produkcyjna staje. Kierownik zmiany dzwoni do działu utrzymania ruchu. Technik pyta, kto ostatnio naprawiał tę maszynę. Okazuje się, że kolega odszedł dwa miesiące temu. Diagnoza zaczyna się od zera, a linia stoi kolejne trzy godziny.
Tymczasem w zakładzie po drugiej stronie miasta identyczna maszyna dostała zlecenie serwisowe; trzy dni wcześniej system wygenerował je automatycznie po tym, jak wskaźnik OEE przez dwie kolejne zmiany spadał poniżej normy. Produkcja nie została zatrzymana ani na minutę.
To nie przypadek. To efekt innej strategii utrzymania ruchu.
Z tego artykułu dowiesz się:
- czym różni się reaktywne, prewencyjne i predykcyjne utrzymanie ruchu,
- kiedy jaka strategia ma sens w zakładzie produkcyjnym,
- dlaczego predykcja nie zawsze jest najlepszym wyborem,
- jak system CMMS wspiera dział utrzymania ruchu,
- jak wybrać strategię UR dla różnych maszyn i stanowisk.
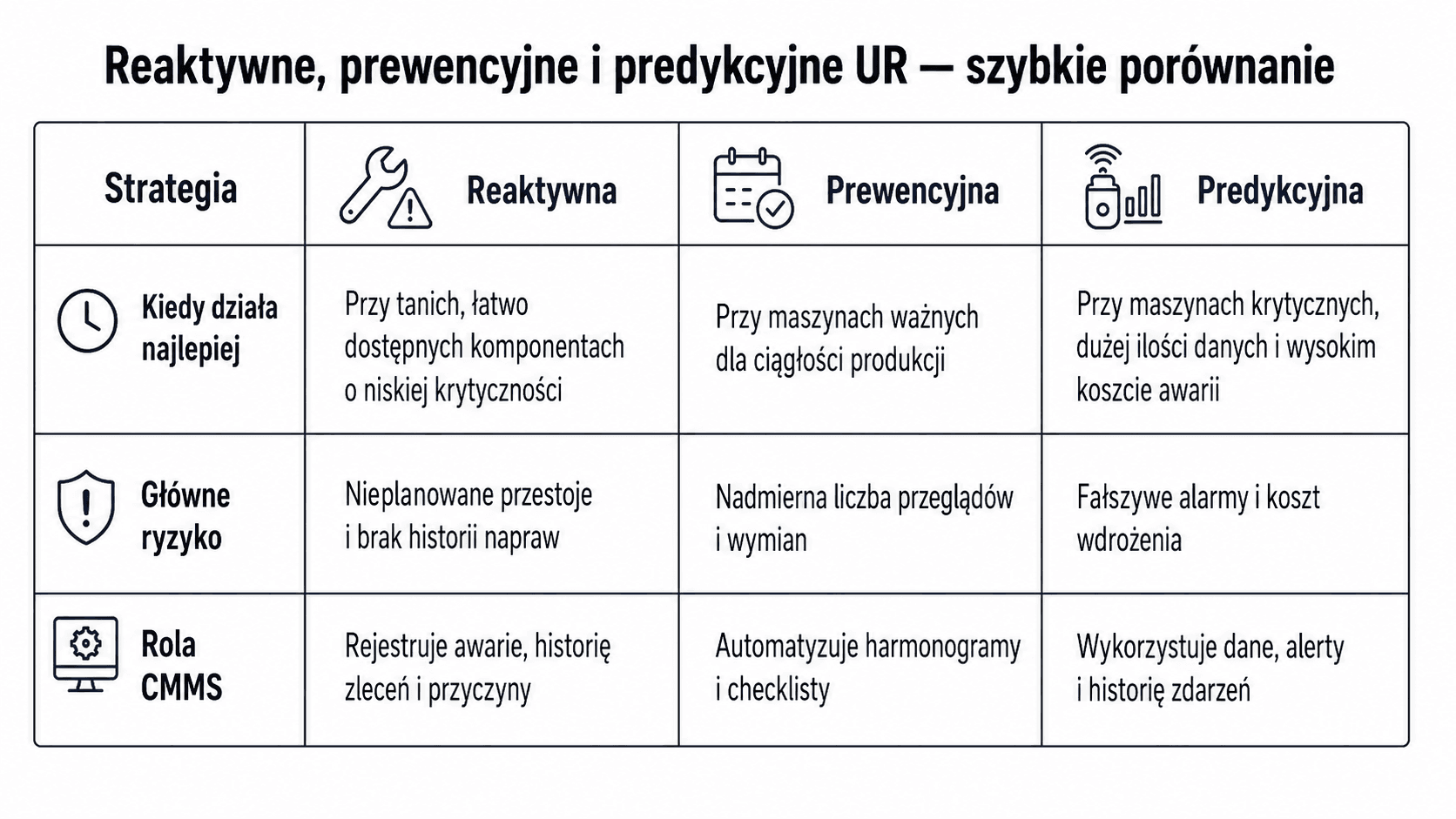
Czym są strategie utrzymania ruchu?
Wybór strategii utrzymania ruchu to jedna z decyzji, która bezpośrednio wpływa na niezawodność parku maszynowego, dostępność linii produkcyjnych i koszty operacyjne zakładu.
Reaktywne, prewencyjne i predykcyjne utrzymanie ruchu nie są modami ani prostymi etapami ewolucji, przez które każda firma musi przejść po kolei. To trzy różne podejścia, które mają inne wymagania, inne koszty wdrożenia i inne obszary zastosowania.
Norma ISO 14224 definiuje strategie utrzymania w kategoriach planowania. Utrzymanie reaktywne, czyli corrective maintenance, jest podejmowane po wykryciu uszkodzenia. Utrzymanie prewencyjne, czyli preventive maintenance, jest wykonywane w z góry określonych interwałach lub według kryteriów stanu technicznego [1]. Predykcyjne utrzymanie ruchu, czyli predictive maintenance, stanowi rozwinięcie podejścia prewencyjnego: przegląd lub interwencję planuje się wtedy, gdy dane wskazują na pogarszający się stan maszyny, a nie tylko dlatego, że wynika to z harmonogramu.
Reaktywne utrzymanie ruchu. Kiedy tani model okazuje się drogi
Reaktywne utrzymanie ruchu, znane też jako run-to-failure, oznacza interwencję dopiero po wystąpieniu awarii lub pogorszeniu działania urządzenia poniżej akceptowalnego poziomu.
Na pierwszy rzut oka to model tani. Nie ma harmonogramów, planowych przestojów ani kosztów prewencyjnych. Dział UR reaguje wtedy, gdy maszyna faktycznie przestaje działać. W niektórych przypadkach jest to w pełni uzasadnione, szczególnie dla urządzeń o niskiej krytyczności, łatwych do zastąpienia i tanich w naprawie.
Problem zaczyna się wtedy, gdy model reaktywny stosowany jest wobec maszyn tworzących wąskie gardła produkcji lub obsługujących krytyczne procesy. W takich przypadkach reaktywność ma wysoką cenę ukrytą w przestojach, defektach, opóźnieniach i utraconych zleceniach.
Badanie opublikowane w International Journal of Prognostics and Health Management przez badaczy NIST, Thomasa i Weissa, przeanalizowało praktyki utrzymania ruchu w amerykańskim sektorze produkcyjnym. Zakłady należące do górnej połowy pod względem stosowania utrzymania reaktywnego odnotowały 52,7% więcej nieplanowanych przestojów oraz 78,5% więcej defektów niż zakłady stosujące podejście prewencyjne lub predykcyjne. W tym samym badaniu zakłady z dominującym modelem reaktywnym poniosły od 49,4% do 73% wyższe straty sprzedaży wynikające z zaburzeń procesu produkcyjnego [2].
Naprawa reaktywna jest też droższa logistycznie. Interwencja odbywa się pod presją czasu, często bez dostępnych części, bez pełnej historii poprzednich zleceń i bez jasnej informacji, co działo się z maszyną wcześniej. U.S. Department of Energy wskazuje, że planowana interwencja prewencyjna jest zazwyczaj znacząco tańsza od naprawy awaryjnej głównie ze względu na brak presji czasowej, lepszą dostępność zasobów i mniejszy zakres uszkodzeń [3].
Kiedy reaktywne utrzymanie ruchu ma sens?
Reaktywność może być właściwą strategią, gdy komponent:
- ma niską krytyczność dla procesu produkcyjnego,
- jest tani w wymianie,
- jest łatwo dostępny w magazynie,
- nie powoduje efektu kaskadowego na inne elementy linii,
- nie wpływa istotnie na bezpieczeństwo ani jakość produktu.
W pozostałych przypadkach model reaktywny powinien być traktowany ostrożnie. To, że firma nie ponosi kosztów prewencji, nie oznacza, że nie płaci za awarie. Często płaci więcej, tylko w mniej widoczny sposób.
Prewencyjne utrzymanie ruchu. Planowanie zamiast chaosu.
Prewencyjne utrzymanie ruchu polega na wykonywaniu przeglądów, kontroli i wymian według ustalonego harmonogramu. Przeglądy mogą być planowane co określony czas, po określonej liczbie godzin pracy lub po określonej liczbie cykli.
To model dobrze znany większości kierowników UR: miesięczne kontrole, wymiana oleju co 500 godzin, kontrola łożysk co kwartał, cykliczne smarowanie węzłów kinematycznych, okresowe przeglądy instalacji lub podzespołów.
Największą zaletą prewencji jest przewidywalność. Dział utrzymania ruchu nie działa wyłącznie w trybie gaszenia pożarów, ale planuje prace, przypisuje zasoby, zamawia części i ogranicza ryzyko nieplanowanych przestojów.
U.S. Department of Energy dokumentuje 12–18% niższe koszty utrzymania dla zakładów z wdrożonym preventive maintenance w porównaniu do podejścia reaktywnego [3]. Eptura w raporcie Workplace Index 2024, opartym na danych z platform zarządzania utrzymaniem, wskazuje, że reaktywne zlecenia serwisowe trwają przeciętnie dwa razy dłużej niż zaplanowane przeglądy prewencyjne. To bezpośrednio wpływa na MTTR i długość przestojów [4].
Główna pułapka prewencji
Prewencyjne utrzymanie ruchu nie jest jednak rozwiązaniem idealnym. Największą pułapką PM jest nadmierna prewencja.
Części bywają wymieniane zgodnie z harmonogramem, mimo że mogłyby działać bez zarzutu przez kolejne tygodnie lub miesiące. Maszyny są zatrzymywane na przeglądy, których częstotliwość wynika bardziej z przyzwyczajenia niż z danych. Technicy realizują czynności, które nie zawsze mają realny wpływ na ograniczenie ryzyka awarii.
McKinsey w analizie strategii utrzymania z 2021 roku wskazuje, że prewencja bywa stosowana niepotrzebnie w znacznym odsetku przypadków. To jeden z głównych argumentów za przejściem od harmonogramów opartych wyłącznie na kalendarzu do podejścia opartego na rzeczywistym stanie maszyny [5].
Dlatego dobrze zaprojektowane prewencyjne utrzymanie ruchu powinno być regularnie weryfikowane. Harmonogramy powinny wynikać z danych: historii awarii, MTBF, MTTR, krytyczności maszyny i kosztu przestoju.
Predykcyjne utrzymanie ruchu. Dane zamiast kalendarza.
Predykcyjne utrzymanie ruchu wzbudza w branży duże zainteresowanie. Uzasadnione, bo kiedy działa, potrafi znacząco ograniczyć liczbę awarii, defektów i nieplanowanych przestojów.
W modelu predykcyjnym interwencja nie wynika wyłącznie z harmonogramu. Decyzja o przeglądzie lub diagnostyce jest podejmowana na podstawie danych: zmiany parametrów pracy maszyny, anomalii, wzorców awaryjności, spadku OEE, powtarzających się statusów awaryjnych lub sygnałów z czujników.
Badanie NIST wykazało, że zakłady z dominującym podejściem predykcyjnym miały 18,5% mniej nieplanowanych przestojów i 87,3% mniej defektów w porównaniu z zakładami stosującymi głównie prewencję [2]. To różnice, których wartość finansowa w skali roku może być bardzo istotna dla zakładu produkcyjnego.
Predykcja nie jest jednak strategią dla każdego i nie zawsze powinna być pierwszym wyborem.
McKinsey opisuje przypadek firmy przemysłowej, która wdrożyła algorytm predykcyjny generujący 10% fałszywych alarmów. W skali całego parku maszynowego oznaczało to ponad 1000 dodatkowych interwencji serwisowych rocznie. Te interwencje wyzerowały oszczędności wynikające z ograniczenia rzeczywistych awarii [5].
Wniosek jest jednoznaczny: predykcyjne utrzymanie ruchu ma największy sens tam, gdzie koszt awarii lub ryzyko dla bezpieczeństwa jest bardzo wysokie, albo tam, gdzie wzorce awaryjności są dobrze rozpoznane i powtarzalne. W pozostałych przypadkach bardziej opłacalne może być condition-based maintenance, czyli monitorowanie stanu bez pełnego modelu predykcyjnego.
Dojrzałość organizacyjna. Dlaczego kolejność ma znaczenie?
Jednym z najczęstszych błędów w organizacjach utrzymania ruchu jest próba wdrożenia predykcji bez wystarczającego fundamentu danych.
Firma wdraża system monitorowania wibracji, podpisuje kontrakt z dostawcą rozwiązań IoT albo uruchamia algorytm analityczny. Po roku okazuje się, że dane z czujników są niespójne, historia zdarzeń praktycznie nie istnieje, a technicy nie ufają alertom, bo zbyt często okazują się fałszywe.
McKinsey w raporcie A Smarter Way to Digitize Maintenance and Reliability wskazuje, że dojrzałe, pełne wdrożenia PdM w przemyśle ciężkim wymagały co najmniej dwóch lat pracy wyspecjalizowanych zespołów i budowania setek modeli analitycznych. Poziom podstawowy PdM, oparty na prostych progach odchyleń i wykrywaniu anomalii, dostarcza mniej niż 10% korzyści pełnego, dojrzałego wdrożenia [6].
Dojrzałość organizacyjną w utrzymaniu ruchu można opisać pięcioma poziomami:
Poziom 1 | Awarie i ich przyczyny są dokumentowane w systemie. Istnieje historia zdarzeń.
Poziom 2 | Harmonogramy przeglądów są zdefiniowane i konsekwentnie realizowane. CMMS zarządza zleceniami.
Poziom 3 | Dane historyczne są analizowane. Dział UR identyfikuje wzorce powtarzalnych awarii.
Poziom 4 | Na podstawie analizy budowane są reguły alertowe. System reaguje na odchylenia od normy.
Poziom 5 | Algorytmy uczenia maszynowego i modele predykcyjne korzystają z dużych zbiorów danych sensorycznych.
Większość zakładów produkcyjnych operuje na poziomie 1–2. To właściwy punkt startowy. Od niego można systematycznie budować wyższą dojrzałość UR pod warunkiem, że dane są zbierane konsekwentnie od pierwszego dnia.
Jak CMMS wspiera strategie utrzymania ruchu?
Niezależnie od tego, na którym poziomie dojrzałości operuje zakład, jedna rzecz jest wspólna dla każdej skutecznej strategii utrzymania ruchu: potrzebny jest system, który zbiera dane, zarządza zleceniami i daje przejrzysty obraz stanu parku maszynowego.
Bez takiego systemu każda awaria zaczyna się od pytania: kto ostatnio naprawiał tę maszynę?
System CMMS porządkuje pracę działu UR. Pozwala rejestrować awarie, tworzyć zlecenia, przypisywać zadania technikom, planować przeglądy, przechowywać historię interwencji i analizować wskaźniki takie jak MTTR, MTBF czy liczba powtarzalnych usterek.
W AndonCloud moduł CMMS integruje się bezpośrednio z systemem Andon. Zmiana statusu stanowiska przez operatora lub przekroczenie zdefiniowanego progu alertowego może automatycznie wygenerować zlecenie pracy w CMMS, bez ręcznej interwencji.
Dział UR otrzymuje zadanie przypisane do konkretnej osoby, z kategorią, priorytetem i historią poprzednich zdarzeń na tym stanowisku. Dzięki temu produkcja i utrzymanie ruchu pracują na tych samych danych w czasie rzeczywistym.
CMMS w modelu reaktywnym
W modelu reaktywnym CMMS nie eliminuje awarii, ale porządkuje reakcję na nie. Każde zlecenie korekcyjne jest tworzone i opisywane w systemie. Technik widzi historię poprzednich napraw, przyczyny awarii, wykorzystane części i czas przywrócenia maszyny do pracy.
Dzięki temu kolejna interwencja nie zaczyna się od zera. Z czasem zakład buduje bazę wiedzy o najczęstszych awariach, najbardziej problematycznych maszynach i rzeczywistych kosztach reaktywnego utrzymania ruchu.
CMMS w modelu prewencyjnym
W modelu prewencyjnym CMMS automatyzuje harmonogramy przeglądów. Zlecenia cykliczne generują się według ustalonego rytmu: co określony czas, po określonej liczbie godzin pracy lub po zamknięciu poprzedniego zlecenia.
Szablony procedur i checklisty zapewniają, że technik realizuje właściwe kroki w ustalonej kolejności. System przypomina o terminach, przypisuje zadania i pozwala analizować, czy harmonogramy faktycznie ograniczają awarie.
CMMS w modelu predykcyjnym
W modelu predykcyjnym CMMS staje się fundamentem danych. Historia zleceń, czasy MTTR, powtarzalność awarii, kategorie przyczyn, statusy stanowisk i zmiany wskaźników OEE tworzą bazę, z której można budować alerty oraz bardziej zaawansowaną predykcję.
W AndonCloud reguły alertowe mogą reagować na odchylenia od normy: powtarzający się status awarii na tym samym stanowisku, spadek OEE poniżej progu przez kilka zmian lub nietypowy wzorzec przestojów. System może wtedy utworzyć zlecenie diagnostyczne zanim dojdzie do pełnej awarii.
To właśnie z takiej historii powstaje realna predykcja. Nie z samego algorytmu kupionego od zewnętrznego dostawcy, ale z własnej bazy wiedzy o własnym parku maszynowym.
Jak wybrać strategię utrzymania ruchu w praktyce?
Wybór strategii UR nie jest decyzją podejmowaną raz na zawsze. Powinien być dopasowany do krytyczności poszczególnych maszyn, dostępności danych i dojrzałości organizacyjnej działu utrzymania ruchu.
1. Zacznij od oceny krytyczności maszyn
Nie każda maszyna w zakładzie wymaga tej samej strategii. Urządzenia krytyczne dla ciągłości produkcji powinny być objęte podejściem prewencyjnym lub predykcyjnym. Maszyny pomocnicze, z łatwo dostępnymi częściami zamiennymi i niskim kosztem przestoju, mogą pracować w modelu reaktywnym.
2. Zbuduj historię, zanim zaczniesz mówić o predykcji
Predykcja bez danych historycznych to algorytm bez kontekstu. Minimum rok systematycznych danych o awariach, czasach napraw i wzorcach zdarzeń jest potrzebny, żeby model predykcyjny miał na czym pracować.
Dane nie muszą od razu pochodzić z zaawansowanych czujników IoT. Punktem startowym mogą być statusy stanowisk, historia zleceń, OEE, MTTR, MTBF, liczba defektów i powtarzalność awarii.
3. Mierz, zanim zaczniesz zmieniać
MTTR, MTBF i OEE powinny być mierzone przed zmianą strategii. Tylko wtedy po kilku miesiącach lub po roku można ocenić, czy zmiana rzeczywiście przyniosła efekt.
Bez punktu odniesienia trudno odpowiedzieć na podstawowe pytania: czy mamy mniej awarii, czy skróciliśmy czas naprawy, czy ograniczyliśmy przestoje, czy poprawiliśmy dostępność maszyn.
4. Rozróżnij MTTR i czas reakcji
MTTR mierzy czas od wystąpienia awarii do przywrócenia maszyny do pracy. Czas reakcji to czas od zgłoszenia problemu do rozpoczęcia działania przez właściwą osobę.
Oba wskaźniki warto mierzyć osobno. Wzrost czasu reakcji często wskazuje na problem organizacyjny, najczęściej opóźnioną komunikację, brak dostępności technika lub niejasne zasady eskalacji. Wysoki MTTR może natomiast oznaczać problem techniczny, brak części, brak procedur albo niewystarczającą historię napraw.
5. Regularnie weryfikuj harmonogramy prewencyjne
Harmonogramy PM nie powinny być ustalane raz na zawsze. Jeśli przeglądy nie ograniczają liczby awarii, trzeba sprawdzić ich zakres, częstotliwość i jakość wykonania. Jeśli części są wymieniane zbyt wcześnie, warto przeanalizować MTBF i przesunąć interwały.
Największy potencjał poprawy często znajduje się tam, gdzie przeglądy są wykonywane „bo zawsze tak było”, a nie dlatego, że potwierdzają to dane.
Jak AndonCloud pomaga budować dojrzałość UR?
AndonCloud łączy system Andon z modułem CMMS, dzięki czemu zdarzenia z hali produkcyjnej mogą automatycznie przechodzić w zlecenia dla działu utrzymania ruchu.
Operator zgłasza problem na stanowisku. System rejestruje status, przypisuje kategorię, zapisuje czas zdarzenia i może wygenerować zlecenie serwisowe. Technik otrzymuje zadanie z priorytetem, historią poprzednich zdarzeń i procedurą działania.
Dzięki temu zakład nie tylko szybciej reaguje na awarie, ale też konsekwentnie buduje historię danych potrzebną do prewencji, analizy powtarzalnych problemów i stopniowego przejścia w stronę utrzymania predykcyjnego.
Chcesz sprawdzić, które maszyny w Twoim zakładzie powinny pracować w modelu reaktywnym, prewencyjnym lub predykcyjnym? Umów się na spotkanie i dowiedz się, jak AndonCloud łączy system Andon z modułem CMMS i pomaga działom UR budować historię awarii, harmonogramy przeglądów oraz reguły alertowe w jednym systemie.
FAQ
Czym jest reaktywne utrzymanie ruchu?
Reaktywne utrzymanie ruchu to strategia, w której interwencja serwisowa następuje dopiero po wystąpieniu awarii lub pogorszeniu działania urządzenia poniżej wymaganego poziomu.
Ten model ma sens dla komponentów o niskiej krytyczności dla procesu produkcyjnego, łatwych do zastąpienia i tanich w naprawie. Sprawdza się tam, gdzie przestój nie powoduje efektu kaskadowego na inne elementy linii. Dla maszyn tworzących wąskie gardła lub obsługujących procesy ciągłe model reaktywny generuje ukryte koszty przestojów, defektów i utraconych zamówień.
Czym różni się utrzymanie prewencyjne od predykcyjnego?
Prewencyjne utrzymanie ruchu opiera się na harmonogramach, a predykcyjne utrzymanie ruchu opiera się na danych o rzeczywistym stanie maszyny.
W prewencji przeglądy i wymiany są wykonywane w ustalonych interwałach czasowych lub po określonej liczbie cykli, niezależnie od aktualnego stanu urządzenia. W predykcji interwencja jest planowana wtedy, gdy wskaźniki kondycji maszyny wskazują na zbliżające się ryzyko awarii. Predykcja może być bardziej efektywna, ale wymaga danych historycznych, infrastruktury pomiarowej i odpowiedniej dojrzałości organizacyjnej.
Czy predykcyjne utrzymanie ruchu zawsze się opłaca?
Nie, predykcyjne utrzymanie ruchu nie zawsze się opłaca. Największą wartość przynosi tam, gdzie koszt awarii jest bardzo wysoki, a wzorce awaryjności są dobrze rozpoznane i powtarzalne.
Od czego zacząć zmianę strategii UR z reaktywnej na prewencyjną?
Zmianę strategii UR z reaktywnej na prewencyjną warto zacząć od systematycznego dokumentowania awarii. Każda awaria powinna być zapisana w systemie z przyczyną, czasem naprawy, zaangażowanymi zasobami i informacją o maszynie. Bez historii zdarzeń nie ma możliwości analizy wzorców, a bez analizy trudno zbudować sensowny harmonogram prewencyjny. Kolejny krok to ocena krytyczności maszyn i określenie, które urządzenia wymagają prewencji, a które mogą nadal pracować reaktywnie.
Co to jest MTTR i czym różni się od czasu reakcji?
MTTR, czyli Mean Time To Repair, to średni czas od wystąpienia awarii do przywrócenia maszyny do pracy.
Czas reakcji oznacza czas od zgłoszenia problemu do rozpoczęcia działania przez właściwą osobę. Oba wskaźniki warto mierzyć osobno, ponieważ pokazują różne problemy. Wysoki czas reakcji często wskazuje na problem organizacyjny, na przykład opóźnioną komunikację lub brak dostępności technika. Wysoki MTTR może oznaczać problem techniczny, brak części lub brak jasnych procedur naprawy.
Czym jest MTBF i jak wykorzystywać go w planowaniu prewencji?
MTBF, czyli Mean Time Between Failures, to średni czas pracy maszyny między kolejnymi awariami.
Rosnące MTBF po wdrożeniu harmonogramów prewencyjnych jest jednym z pierwszych mierzalnych sygnałów, że strategia działa. MTBF pomaga też optymalizować częstotliwość przeglądów. Jeśli maszyna psuje się średnio co 120 godzin, przegląd co 100 godzin może być uzasadniony. Przegląd co 50 godzin może natomiast oznaczać nadmierną prewencję i generować niepotrzebne koszty planowanych przestojów.
Jak CMMS wspiera strategię prewencyjnego utrzymania ruchu?
CMMS wspiera prewencyjne utrzymanie ruchu przez automatyzację harmonogramów, zleceń cyklicznych, checklist i przypisań zadań.
W AndonCloud zlecenia cykliczne mogą generować się automatycznie według zdefiniowanego rytmu. Technik nie musi pamiętać o terminie. System tworzy zadanie po zamknięciu poprzedniego zlecenia lub zgodnie z ustalonym harmonogramem. Szablony procedur z wymaganymi krokami checklisty pomagają realizować przeglądy konsekwentnie, niezależnie od doświadczenia osoby wykonującej zlecenie.
Jak AndonCloud łączy system Andon z modułem CMMS?
AndonCloud łączy system Andon z modułem CMMS w taki sposób, że zdarzenie z hali produkcyjnej może automatycznie wygenerować zlecenie dla działu utrzymania ruchu.
Takim zdarzeniem może być zmiana statusu stanowiska przez operatora, przekroczenie zdefiniowanego progu alertowego lub powtarzający się wzorzec awarii. Technik otrzymuje zadanie z przypisaną kategorią, priorytetem i historią poprzednich zdarzeń na tym stanowisku. Dzięki temu dział UR i produkcja działają na tych samych danych w czasie rzeczywistym.
Czy predykcja wymaga drogich czujników IoT?
Predykcyjne utrzymanie ruchu nie zawsze musi zaczynać się od drogich czujników IoT.
Punktem startowym mogą być dane już dostępne w zakładzie: historia statusów stanowisk, wskaźniki OEE, czasy awarii, liczniki defektów, MTTR, MTBF i powtarzalność zleceń serwisowych. Zaawansowane czujniki drgań, temperatury czy prądu rozszerzają możliwości, ale predykcja oparta na wzorcach zdarzeń z systemu Andon i CMMS może dostarczać wartościowych sygnałów bez dodatkowej infrastruktury sensorycznej.
Źródła
[1] ISO 14224:2016. Petroleum, petrochemical and natural gas industries — Collection and exchange of reliability and maintenance data for equipment. International Organization for Standardization.
[2] Thomas, D. and Weiss, B. (2021). Maintenance Costs and Advanced Maintenance Techniques in Manufacturing Machinery: Survey and Analysis. International Journal of Prognostics and Health Management, 12(1). DOI: 10.36001/ijphm.2021.v12i1.2883. PMC9890517.
[3] U.S. Department of Energy (2010). Operations & Maintenance Best Practices Guide. Release 3.0. Federal Energy Management Program.
[4] Eptura (2024). Workplace Index H1 2024 Report. eptura.com.
[5] McKinsey & Company (2021). Establishing the right analytics-based maintenance strategy. McKinsey Operations Practice, lipiec 2021.
[6] McKinsey & Company (2021). A smarter way to digitize maintenance and reliability. McKinsey Operations Practice, kwiecień 2021.
